
ある統計資料から 10 人の男性のデータを無作為抽出したら身長と体重の関係は次のようであったとします。
| 番号 | 身長 x [cm] | 体重 y [kg] |
|---|---|---|
| 1 | 169.14 | 56.91 |
| 2 | 183.27 | 70.95 |
| 3 | 156.3 | 52.45 |
| 4 | 176.08 | 77.17 |
| 5 | 165.91 | 68.8 |
| 6 | 166.2 | 56.03 |
| 7 | 172.17 | 71.6 |
| 8 | 172.91 | 61.58 |
| 9 | 168.27 | 78.06 |
| 10 | 170.43 | 67.91 |
身長が大きければ体重も大きくなるであろうと予測できますが、太っている人も痩せている人もいますから、身長と体重はきれいな比例関係にあるわけではなく、グラフにプロットしても直線になるわけではありません。
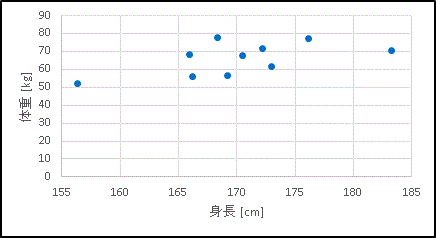
それでも、この2つのデータは近似的に直線に乗るだろうと考えて、各個のデータとの間になるべく誤差が少ないような直線を当てはめてみようというのが最小二乗法(method of least squares)の考え方です。
最小二乗法
2つの変量 $x,\:y$ について、大きさ $n$ の標本の組
\[(x_1,y_1),\:(x_2,y_2),\:\cdots\:(x_n,y_n)\]
があり、$x$ と $y$ の間に近似的に
\[y=ax+b\tag{1}\]
という比例関係があると仮定します。$(x_i,y_i)$ と直線 (1) との誤差を
\[e_i=y_i-(a+bx_i)\quad (i=1,\:2,\:\cdots,\:n)\tag{2}\]
で表します。この式を線型回帰モデル(liner regression model)とよびます。(2) の i についての総和
\[Q(a,b)=\sum_{i=1}^{n}e_i=\sum_{i=1}^{n}[y_i-(a+bx_i)]^2\tag{3}\]
が最小となるような係数 $a,\:b$ を決定します。すなわち
\[\frac{\partial Q}{\partial a}=0,\quad\frac{\partial Q}{\partial b}=0\]
となるような $a,\:b$ を求めます。この式に (3) を代入すると
\[\sum_{i=1}^{n}y_i-na-b\sum_{i=1}^{n}x_i=0\tag{4}\]\[\sum_{i=1}^{n}x_iy_i-a\sum_{i=1}^{n}x_i-b\sum_{i=1}^{n}x_i^2=0\tag{5}\]
という方程式が得られます。ここで $x$ の標本平均と標本分散を $\bar{x},\:s_x^2$ とし、$y$ の標本平均と標本分散を $\bar{y},\:s_y^2$ とします。また $x$ と $y$ の標本共分散を $s_{xy}$ とします:
\[\begin{align*}\bar{x}&=\frac{1}{n}\sum_{i=1}^{n}x_i\tag{6}\\[6pt]\bar{y}&=\frac{1}{n}\sum_{i=1}^{n}y_i\tag{7}\\[6pt]s_x^2&=\frac{1}{n}\sum_{i=1}^{n}x_i^2-\bar{x}^2\tag{8}\\[6pt]s_y^2&=\frac{1}{n}\sum_{i=1}^{n}y_i^2-\bar{y}^2\tag{9}\\[6pt]s_{xy}&=\frac{1}{n}\sum_{i=1}^{n}x_iy_i-\bar{x}\bar{y}\tag{10}\end{align*}\]
これらを全て式 (4) と (5) に入れると
\[\begin{align*}&\bar{y}-a-b\bar{x}\tag{11}\\[6pt]&s_{xy}+\bar{x}\bar{y}-\bar{x}a-(s_x^2+s_y^2)b=0\tag{12}\end{align*}\]
となります。この式を $a,\:b$ について解いて、標本相関係数
\[C_{xy}=\frac{s_{xy}}{s_x s_y}\tag{13}\]
を定義すると
\[a=\bar{y}-C_{xy}\bar{x}\frac{s_y}{s_x},\quad b=C_{xy}\frac{s_y}{s_x}\tag{14}\]
となります。この係数を標本回帰係数 (sample regression coefficient) とよびます。すなわち回帰直線は
\[y-\bar{y}=C_{xy}\frac{s_y}{s_x}(x-\bar{x})\tag{15}\]
で与えられます。
誤差分散と相関係数の意味
残差平方和 $Q$ を $n$ で割った
\[s_e^2=\frac{Q}{n}=\frac{1}{n}\sum_{i=1}^{n}e_i^2\]
は誤差の分散を表しています。すなわち
\[s_e^2=\frac{1}{n}\sum_{i=1}^{n}[y_i-(a+bx_i)]^2\]
であり、
\[\bar{y}-a-b\bar{x}\]
を用いて $a$ を消去すると
\[s_e^2=\frac{1}{n}\left[\sum_{i=1}^{n}(y_i-\bar{y})^2-2b\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})+b^2\sum_{i=1}^{n}(x_i-\bar{x})^2\right]\]
という式が得られます。ここで
\[\begin{align*}&s_x^2=\frac{1}{n}\sum_{i=1}^{n}x_i^2-\bar{x}^2,\qquad s_y^2=\frac{1}{n}\sum_{i=1}^{n}y_i^2-\bar{y}^2\\[6pt]&s_{xy}=\frac{1}{n}\sum_{i=1}^{n}x_iy_i-\bar{x}\bar{y},\qquad b=\frac{s_{xy}}{s_x^2}\end{align*}\]
を全て入れると
\[s_e^2=s_y^2-\frac{s_{xy}^2}{s_x^2}\]
となります。$C_{xy}=s_{xy}/(s_xs_y)$ を用いると
\[s_e^2=s_y^2(1-C_{xy}^2)\tag{16}\]
という誤差の分散と相関係数の関係式が得られます。相関係数 $C_{xy}$ は 0 から 1 の値をとるので、その絶対値が大きいほど誤差の分散が小さくなり、2つの変量(データ)同士の関連性が強いという可能性を示しています。0 であればほぼ無関係です。ただし、相関係数はあくまで目安なので、標本の取り方によって偶然 “直線的になった” というケースもあるので注意が必要です。
また $C_{xy}$ は直線の傾きも表しています。$C_{xy}$ が正のときには「正の相関がある」、負のときには「負の相関がある」といいます。たとえば気温を $x$, ヒーターの売れ行きを $y$ とするなら、(暑い時にヒーターなんてほとんど売れないでしょうから)、そのデータには負の相関があるはずです。ちなみに記事の冒頭にある身長と体重のデータを用いて相関係数を計算すると約 0.58 となります。
【Excel】回帰直線のプロット
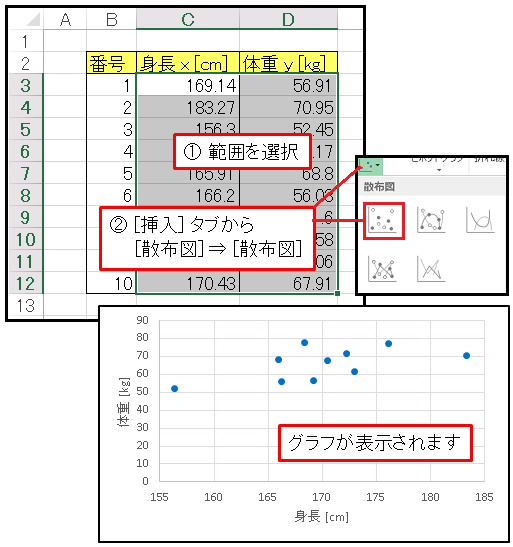
Excel は上で述べたような計算を全て自動で行なってくれます。記事の最初に載せてある身長と体重の表をコピーしてセル B2 に貼りつけてください。そのあとセル C3:D12 を選択した状態で [挿入] タブから [散布図] ⇒ [散布図] を選択するとグラフが表示されます。
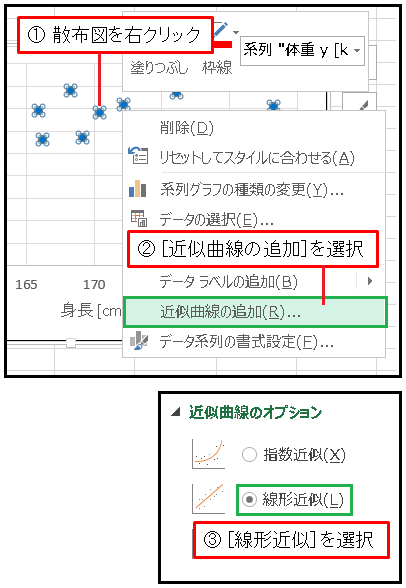
次は回帰直線を表示させてみます。散布図を右クリックして現れたメニューから [近似曲線の追加] を選択します。[近似曲線のオプション] で [線形近似] を選択してください。
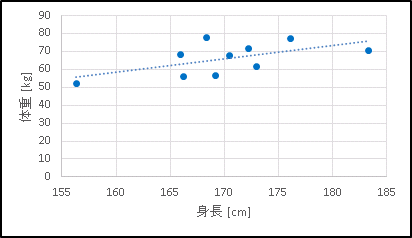
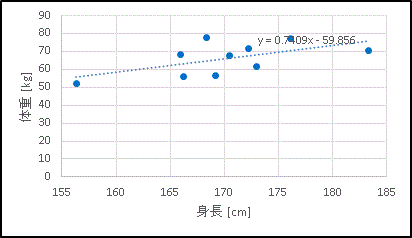
すると次のような回帰直線が表示されます。
これだけでは係数の値がわからないので、数式も表示させてみましょう。近似曲線を右クリックして [近似曲線の書式設定] を選択します。[グラフに数式を表示する] にチェックを入れてください。
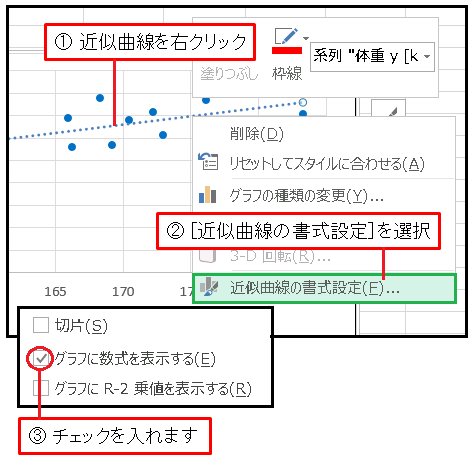
小さな文字で数式が表示されます。
あとは回帰直線の線の色や数式の文字の大きさなどを好みに応じて適当に調整します。
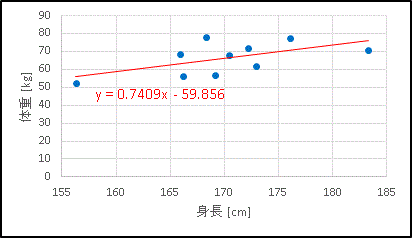
これでグラフの完成です。
エクセルや数学に関するコメントをお寄せください