
統計分析の練習用にサンプルデータが欲しい時がありますが、ネットを探しても思うようなデータはなかなか見つかりません。公開されているデータの多くは統計処理済みですから、そこに載っているのは(たとえば身長や体重などの)平均値や標準偏差などです。バラつきのある生のデータを無料で手に入れることは案外難しいのです。
【Excel】人工統計データの作成方法
当サイトでは現実の状況に基づいた人工的な統計データを作成する Excel ファイルを提供します(一般の Excel ユーザーが機能を拡張しやすいように、VBA を使わずに Excel だけで作成してあります)。データは厚生労働省が公開している「日本人男性の年齢別人口分布表」と「日本人男性の平均身長と標準偏差」を加工して作成しました。以下のファイルをダウンロードして開いてから、「編集を有効にする」をクリックしてください。
➡年齢と身長データ作成ファイルをダウンロード
使い方は簡単です。J 列と K 列に人工的に作成された 100 人分の年齢と身長のデータが並んでいます。[F9] キーを押すと乱数が更新されて別のデータが作成されます。ここで作成されるデータは、現実に無作為に 100 人を選んで身長のデータを取得した場合と同じような分布になります。乱数が更新されるときに目がちらついて煩わしいと感じる場合は、H 列と I 列のセルを非表示にしておいてください。
機能を拡張してみたいというユーザーのために、動作の仕組みも簡単に解説しておきます。ワークシートの概要は以下のようになっています。
[1] 実際の年齢別人口分布をもとに「年齢別人口累積分布データ」を作成。
[2]「年齢決定乱数」を発生させて「人口累積分布」から年齢をランダムに決定。
[3] 年齢に対応した平均身長と標準偏差を取得。
[4]「身長決定乱数」を発生させて、身長分布(正規分布)の累積分布関数の逆関数を用いて身長を決定。
ファイルを開くと、シートの左側には次のような表があります。
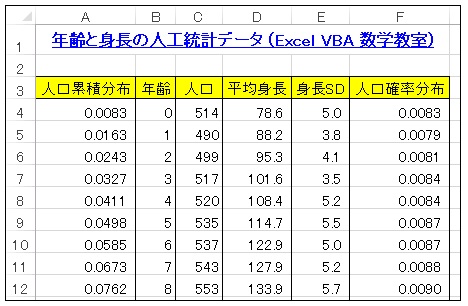
これは、合計 61768 人の年齢別人口分布と、年齢別平均身長/標準偏差 (SD) を統合した一覧表です。人口確率分布は、ある年齢の人が全体のうちに占める割合(人口比率)を示す数値で、
[ある年齢層に属する人数] / [全体の人数 (61768)]
という式で計算されます。人口累積分布は人口確率分布を階級ごとに加えた値です。たとえば、0 歳と 1 歳の人口比率はそれぞれ 0.0083 と 0.0079 なので、0 歳と 1 歳を合わせた数の全体に占める割合は
0.0083 + 0.0079 = 0.0162
となります。0 から 1 の乱数を発生させたとき、0.0083 未満なら 0 歳、0.0083 ~ 0.0162 なら 1 歳というように年齢を無作為に決定することができます。ただし、VLOOKUP 関数の構文に合わせて、累積分布は 1 行ずつ下にずらしています。年齢と累積確率のデータをプロットすると下図のようになります。
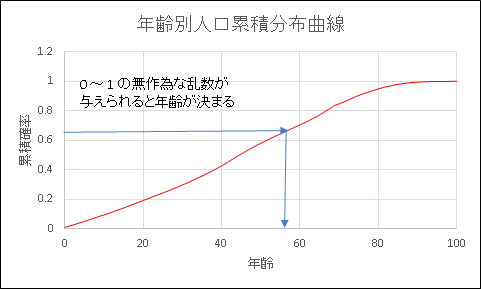
このデータでは近似的に 100 歳以上をすべて 100 歳にしてあるので、年齢が 0 ~ 100 歳の範囲にある確率は 1 となります。0 ~ 1 の乱数を変数にとると、累積分布関数の逆関数として年齢を無作為に定めることができます。この乱数は「年齢決定乱数」としてシートの右側の表にある H 列に並んでいます。
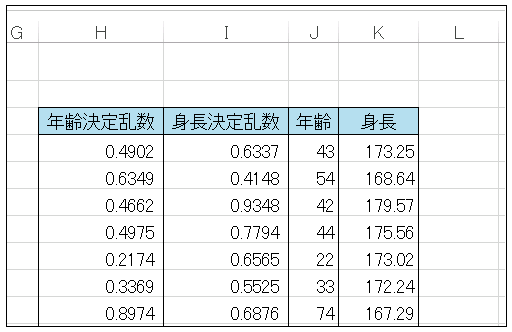
J 列では、この「年齢決定乱数」を引数として受け取った VLOOKUP 関数が、左側の表の A 列に並ぶ「人口累積分布」から「年齢決定乱数」より小さく最も近い値を探し出して、B 列に記載された年齢を表示します。たとえばセル J4 には
=VLOOKUP(H4,$A$4:$F$104,2,TRUE)と入力されています。第 4 引数に TRUE を指定することで、完全一致ではなく近似値を探すようにしています。
ある人の年齢が定まると、左側の表から平均身長と身長の標準偏差 (SD) が与えられます。身長の分布は正規分布にしたがうことが知られています。0 ~ 1 の乱数が与えられると、正規分布の累積分布関数の逆関数として身長を決定することができます。Excel には NORM.INV という累積分布関数の逆関数を計算する関数が用意されています。
=NORM.INV(確率,平均,標準偏差)年齢に対応した平均と標準偏差を参照するので、第 2 引数と第 3 引数には VLOOKUP 関数をネストします。たとえばセル K4 には
=VLOOKUP(NORM.INV(I4,VLOOKUP(J4,$B$4:$F&$104,3), VLOOKUP(J4,$B$4:$F$104,4)),2)という式が入っています。
エクセルや数学に関するコメントをお寄せください